Context is Everything
Context engineering is the natural evolution of prompt engineering. While both share the same goal—getting the best results from AI models—context engineering is a much entertained science!
I love how Shopify's CEO Tobi Lütke describes it:
I really like the term "context engineering" over prompt engineering.
— tobi lutke (@tobi) June 19, 2025
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
With RAG, MCPs, File Systems, Memory... the promise has arrived: AI systems can understand their environment proactively. Totally badass!
This brings us to the next point: Context is everything. From system messages, tools, memory… the good news? Each of these is an opportunity to optimize.
Context engineering is about seizing that opportunity—deciding what information to provide and how to deliver it to create reliable systems that give the best responses.
How do we know if we can squeeze more out of it, or if the model has hit its limit?
We don't. The challenge is pushing boundaries until we reach the model's capacity, while recognizing those limits to avoid over-engineering. Later we'll explore various factors and mechanisms to bend the rules a bit.
Garbage in, garbage out
LLMs are pure functions. Quality input = Quality output. Data quality takes on a new magnitude and dimension with AI.
Magnitude because, as we've seen, it's highly dependent—applying the law of leverage in both directions. A single word can contaminate an entire response. And the performance margin operates at a superior scale.
The dimensions:
- Correctness - Obvious, yet still not solved
- Completeness - Bad AI responses expose our communications flaws, we have not give a clear instruction.
- Size - Manage token usage efficiently by compressing or summarizing content to balance performance, cost, and context window limits
- Trajectory - Structure information in a logical order and maintain coherent progression throughout the conversation or data sequence. More recent, more hypothesis-driven. Distribution matters: you can place context in a system message or a user message. Thread state. Optimizing every single token.
What to avoid:
- Incorrect Context - The easiest way to make an LLM dumber is feeding it contradictory, obsolete, outdated, or factually wrong information
- Missing Info - When the LLM lacks data, it tends to fill those gaps—that's when hallucination occurs
- Too Much Noise - Anything that doesn't contribute to generating the response is irrelevant information that clutters the context window and dilutes model focus
Why don't just use long context?
The latest updates from Gemini, Claude, and co. announce context windows (the amount of info you can feed them) of +1 million tokens, the equivalent of 10 novels. And the results of their corresponding benchmarks, like the Needle-In-The-Haystack (NITH), are definitely inspiring.
The reality is just as slightly different. Firstly, because these evaluations (NITH) are far from the type of effort required in a real-world environment, mainly because it's a task that doesn't need reasoning.
Diminishing Returns
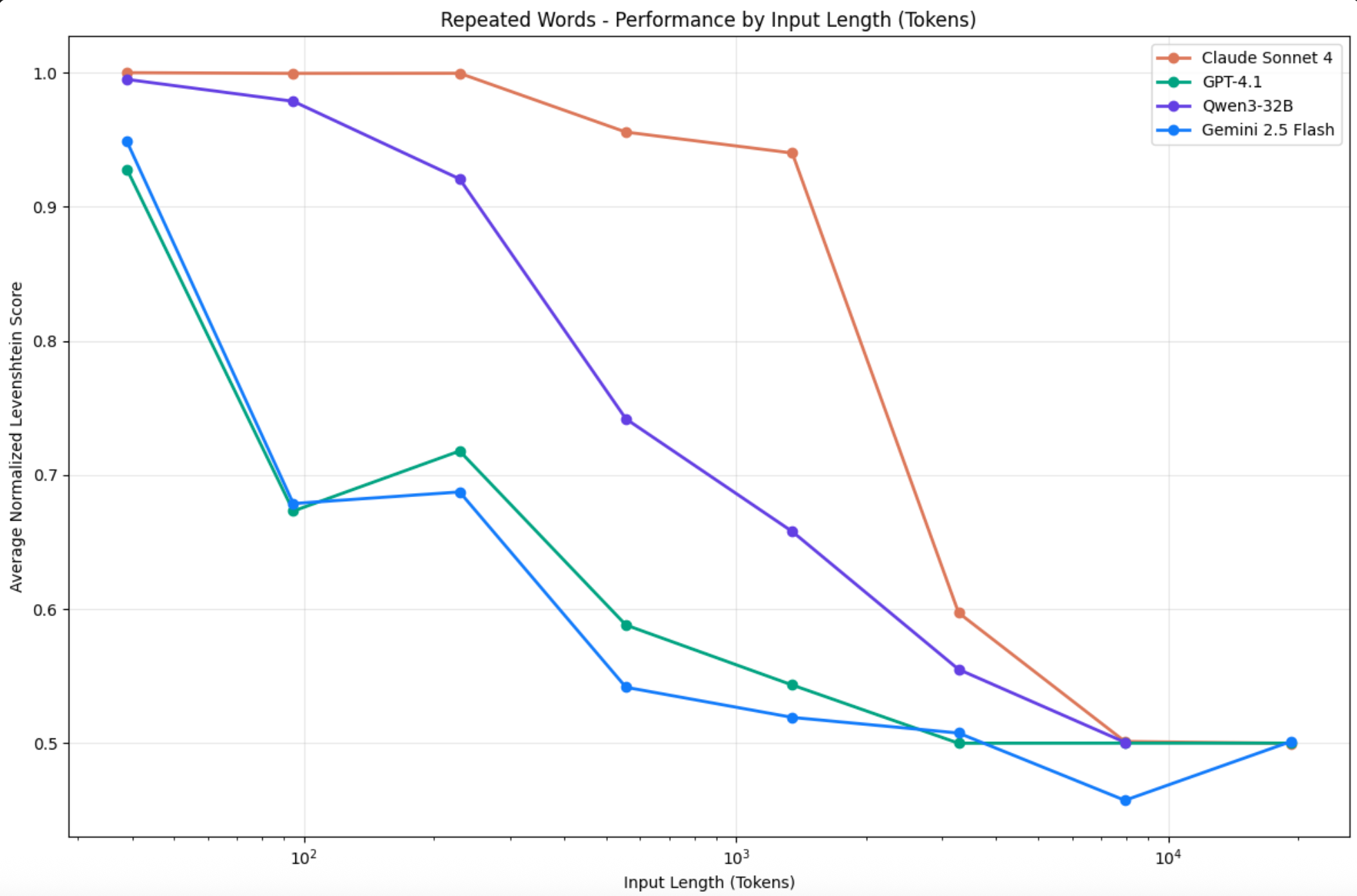
And secondly, because we see a clear diminishing return in model performance beyond a certain amount of input.
The Research Lab at Fount Chroma conducted a study that shows this evidence in a simple word-repetition exercise.
That sweet spot is different for every model and every situation, but it helps us set a clear standard. And that's the beauty of it!
So what is the effective context window?
We already know the answer: IT DEPENDS!
The goal is to balance two extremes: use as minimal context as possible, but provide the most context (information) possible.
But darn it, we want an estimate! Several of the industry's top experts talk about how context performance decreases when you drop below 40% of the total context window capacity. In my experience building Clous, the AI-native system for HR, I made that estimate. I just didn't have the budget to validate it. Other like Geoffry Huntley suggest that the current practical capacity is around 170K tokens.
Context windows have limits, but real work doesn't
The problem gets worse with agents, as they have to manage complex tasks that usually involve multiple tool calls. This quickly saturates the effective context window, often preventing the workflow from finishing or significantly reducing performance.
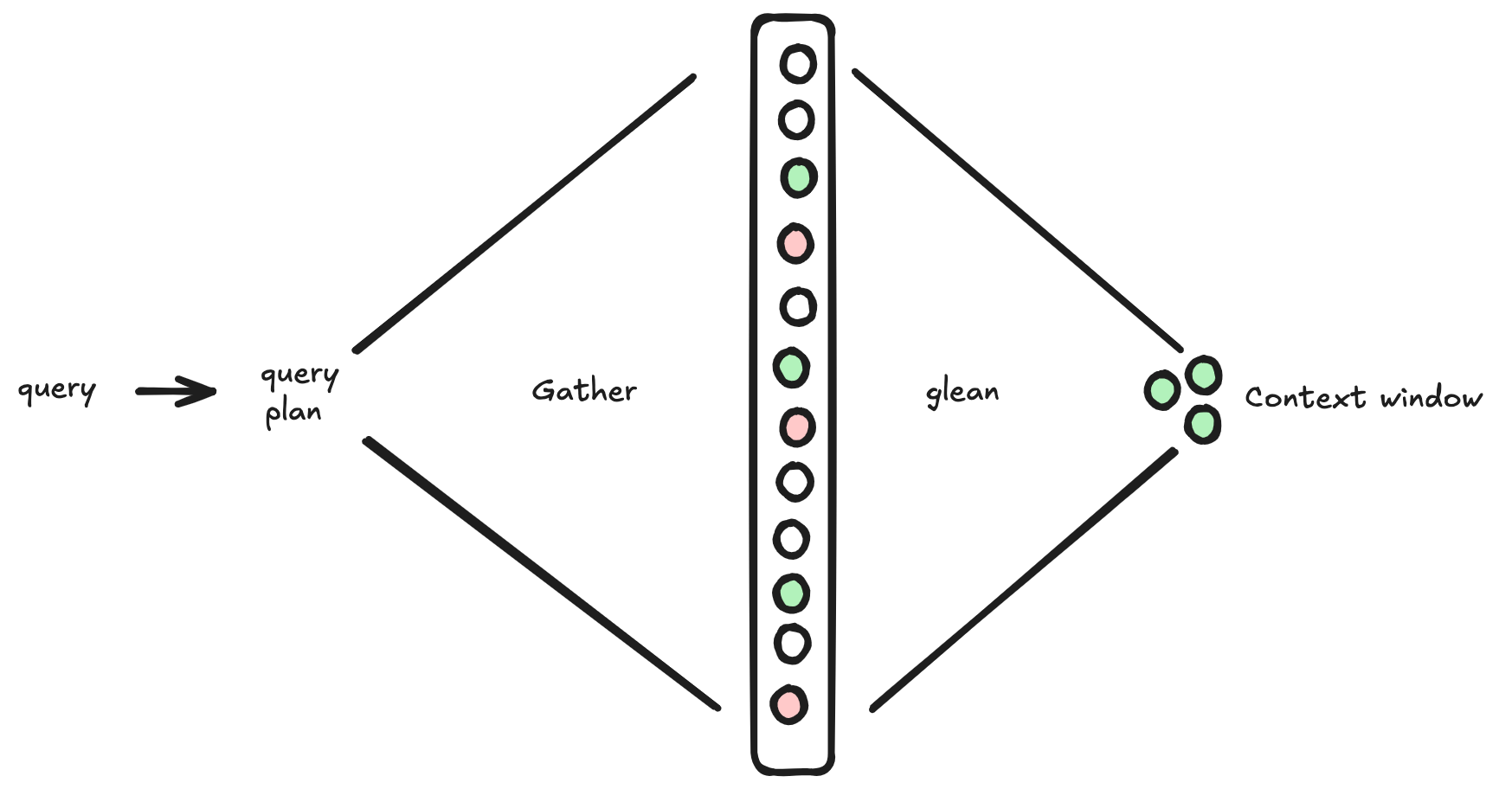
Context management solves this in two ways: it helps developers ensure that only relevant data stays in context and that valuable insights are preserved across sessions.
I love how Jeff Huber divides the process into two parts:
- Gather: Maximize info retrieval (which may include non-relevant info).
- Glean: Extract the most relevant and necessary info for the model.
Intentional Compaction
Giving the model exactly what it needs to know is the goal. We reduce all the noise so the model can focus on the relevant info. See Kolmogorov's complexity theory — the shortest description of data). The task is to optimize every single token.
Can we give the model the same info but with fewer tokens? Keeping in mind how the model understands data is based on how it has been trained.
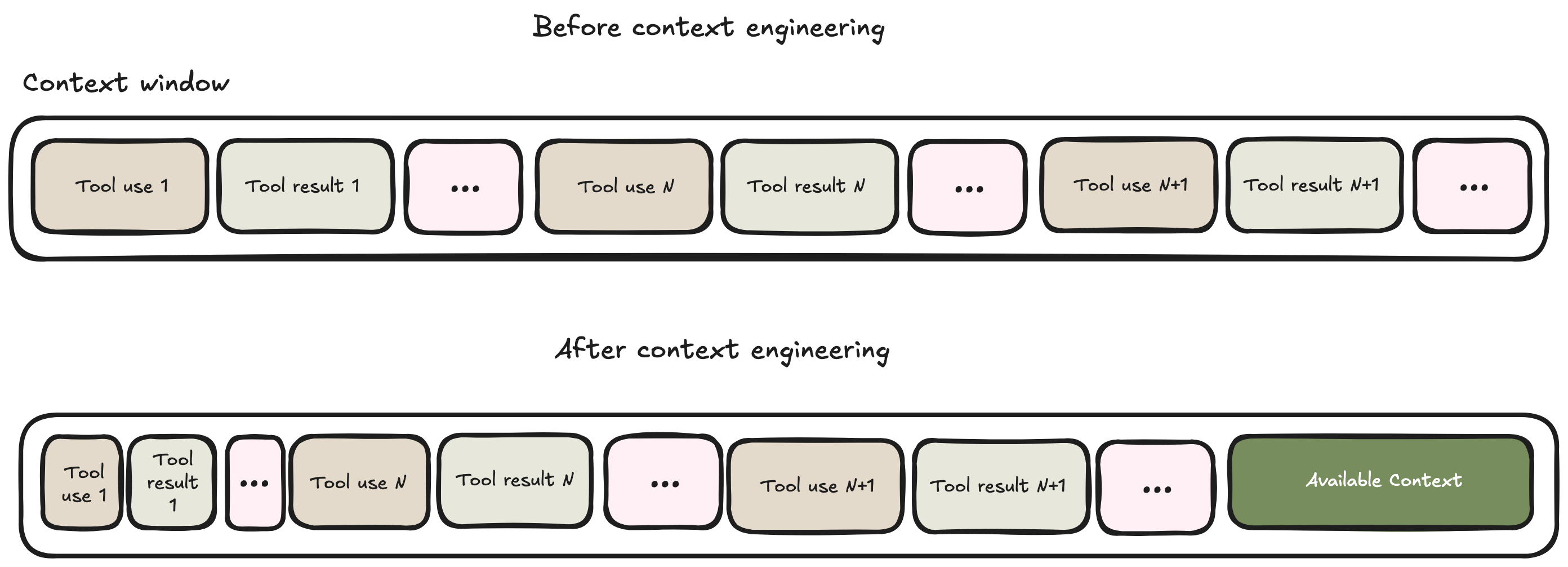
In-line Compaction
As we've seen, agents accumulate context from previous runs, especially from tool calls. It's easy to get your context window flooded with irrelevant data.
In-line compaction handles long-running tasks at higher performance without hitting context limits or losing critical information.
Building mechanisms to compact the context while the agent is executing permits freeing up effective space.
We've all cried trying to solve an issue and getting stuck in the same thread. Starting a new thread is often recommended by OpenAI experts.
Great examples are compacting errors. Tool call errors are useful to prevent the model from repeating the same operations, but it's not necessary to save all the details.
- Summarize
- Limit loop
- Clear once you get a valid response
You can build this mechanism yourself, but principal AI providers are already working on it. Claude, for instance, just released a context management feature, combining the memory tool with context editing, which improved performance by 39% over baseline.
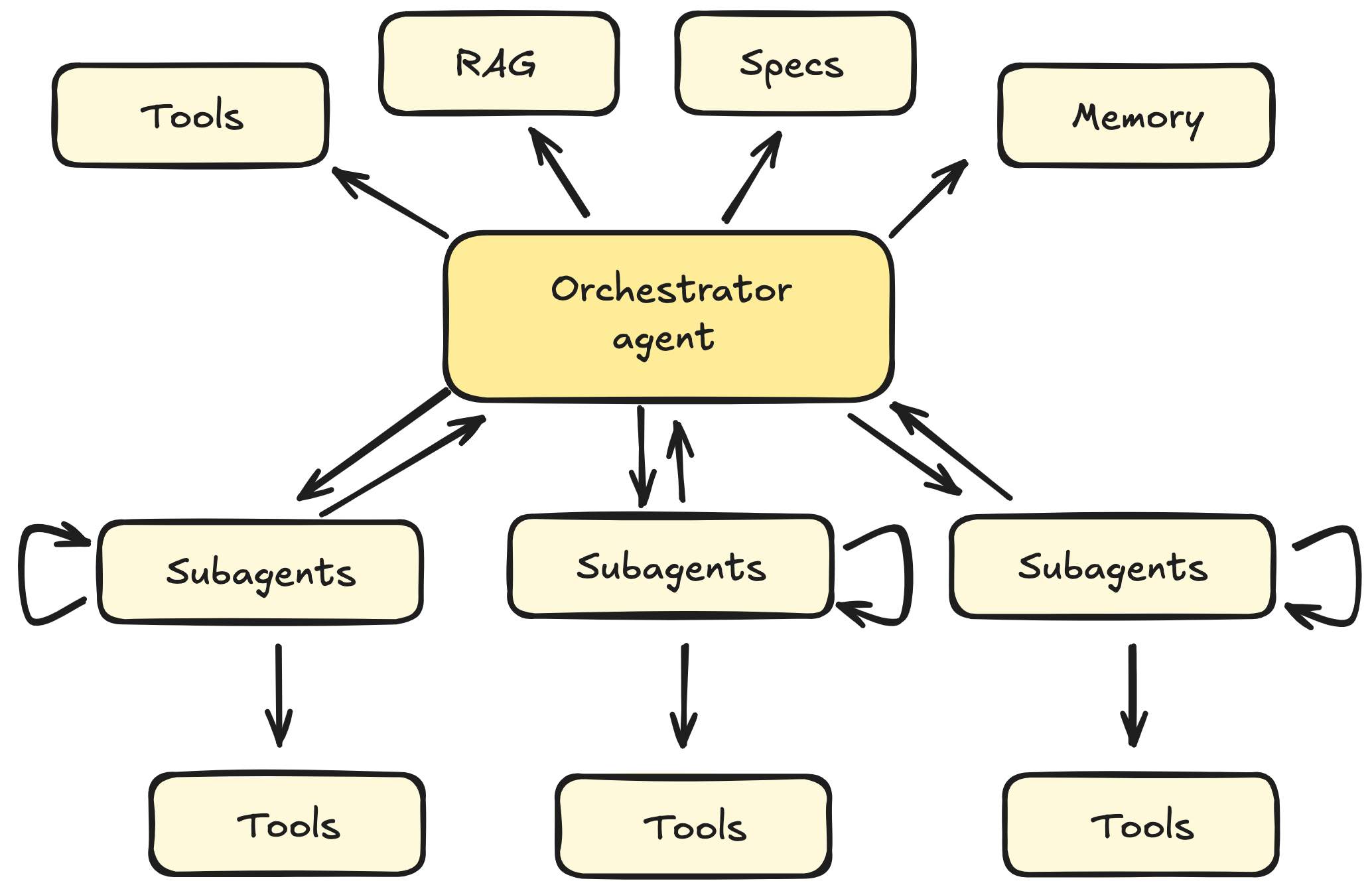
Context Control and Orchestration
Context engineering is fundamentally about context controls. We have to take into account the context window limits, but also the AI operations, as the wrong context can contaminate the end result.
It's useful to break down the task, so we can:
- Maintain certain independency from different call results.
- Also allows us to be more efficient with parallel tool calls (this is a whole other issue!).
- Widen the effective context window.
It's common to use an agent orchestrator with micro-agents to distribute the context windows into sub-parts and ensure performance.
Abstraction
When the task is ambiguous and involves a lot of functionality, it's difficult for LLMs to choose the ideal tool to call. To solve this, it's useful to raise the layers of abstraction.
One of the best examples is with MCPs. Unlike traditional APIs, where description and naming are straightforward, LLMs can easily get lost in an infinite number of function calls. So, instead of listing all the function calls as you would normally with APIs, what you can do is unify various tools into one function and let the AI adjust the parameters and choose the specific tool within that function.